
Many Hands Make Light Work: Leveraging Collective Intelligence to Align Large Language Models
Published:
Multi-Reference Preference Optimization (MRPO) for Large Language Models (AAAI 2025)
Table of Content
- For AI, Alignment Matters
- What is Preference Optimization?
- Direct Preference Optimization and Its Limitations
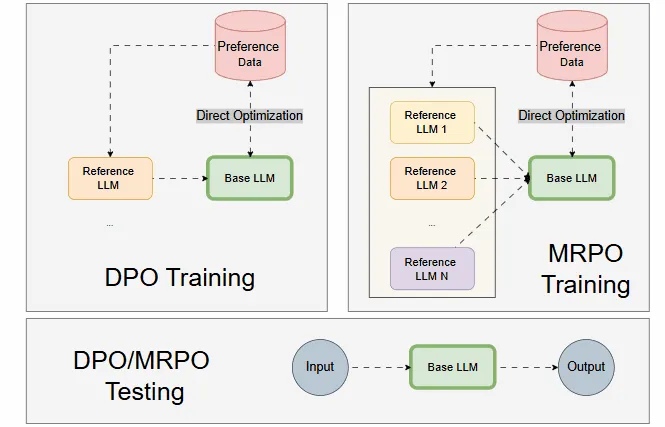
- Enter MRPO: A Paradigm Shift
- Key Idea: Leveraging Multiple Reference Models Efficiently
- Why Is Efficient Multi-Reference Not Easy?
- How MRPO Builds on DPO
- The Nuts and Bolts of MRPO
- Stable Alignment with Clipped Trust-Regions Optimization
- Automatic Reference Crediting with Adaptive Reference Weighting Coefficients
- Key Achievements and Future Directions
- Performance with Limited Preference Data
- Scalability to Large Datasets
- Appendix
For AI, Alignment Matters
In the rapidly evolving field of AI, alignment ensures that large language models (LLMs) generate accurate outputs and resonate with human values, preferences, and expectations. Without alignment, these powerful models risk producing content that may be misleading, offensive, or misaligned with user needs.
Imagine asking a language model for advice on a sensitive topic. Without proper alignment, the response might be factual but lack empathy, or worse, it could inadvertently reinforce biases or deliver information that feels detached or even offensive. Alignment bridges this gap, ensuring that these AI systems aren’t just smart but also socially aware, user-focused, and culturally nuanced.
However, achieving alignment is no small feat. These models are trained on vast datasets spanning multiple domains and contexts. While this makes them incredibly versatile, it also means they can inherit biases or fail to understand the subtleties of human preference. For instance, if the training data primarily consists of texts about drills, the LLM may be biased towards generating related content, even when prompted to write about hammers.