
Human-Aligned Large Language Models
Published:
About recent LLM alignment finetuning techniques such as RLHF, DPO, KTO, IPO and SPIN
Table of Content
- A Bit of Context
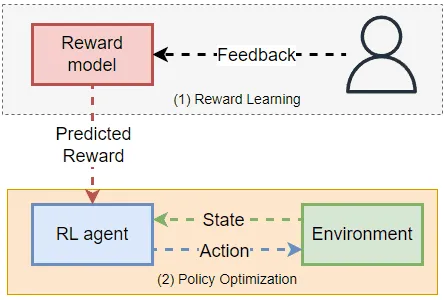
- Reinforced Finetuning using Reward Model
- Reward Learning
- Policy Optimization
- AI Feedback
- Preference Optimization without RL
- Direct Preference Optimization (DPO)
- Alternative Preference Optimization
- Self-Play Preference Optimization
- Finetuning with Rating Feedback
A Bit of Context
In alignment training, the goal is to ensure that the outputs generated by machine learning models align closely with human preferences, values, and intentions. The research traces back to the classic era of machine learning, studying preference models to support various tasks in classification and reinforcement learning [1,2]. Until 2017, researchers have scaled up the approach and employed reinforcement learning algorithms such as PPO in aligning models to predict according to human preference [3]. As Large Language Models become more prevalent, alignment training emerges as a crucial factor in their success, especially in the case of Chat-GPT. The LLM finetuning framework generally consists of two steps:
Supervised finetuning: LLM is finetuned on data with ground truth labels for the task.
Alignment finetuning: LLM is finetuned on human feedback data, often in the form of preference such as comparison feedback.
🧠 Why is alignment necessary instead of keeping supervised fine-tuning?
Limited training data leads to overfitting with excessive fine-tuning.
Obtaining more supervised data requires costly labeling of ground truth answers.
Supervised fine-tuning using LLM is expensive and does not prioritize generating user-desired outputs.
👉 This article focuses on step 2: LLM alignment. A common scheme for alignment training is to use feedback-based labels as training signals to reduce the labeling cost. Another consideration is that the finetuned model should not deviate too much from the base model, ensuring that the final model retains the properties learned from extensive pretraining and supervised tuning data.
Check our papers: