Memory in Reinforcement Learning: Overview
Published:
Memory is just storage. Whenever computation needs to store interim results, it must ask for memory. This fundamental principle applies to any scenario where memory is required, yet a closer interpretation of memory’s role in each domain reveals a different understanding of its functionality and benefit.
In RL, the notation of memory varies depending on the form and purpose. For instance, as briefly mentioned in the previous post, the replay buffer in DQN is a memory storing raw observations represented as tuples $(s_t,a_t,s_{t+1},r_t)$. The agent uses them as experiences and relies on them to make wise decisions in the future. The purpose is similar to a value table $V(s_t)$ in classical model-free RL: to aid decision-making and build value estimation. However, the granularity of a replay buffer and a value table are not alike. The former is raw, containing unprocessed information on the environment while the latter is sophisticated and represents knowledge of the optimal values for each state. Because the replay buffer is primitive, it is fast to process and ready to use at any time. Imagine that all one needs is to insert a new tuple to the buffer and sample some when he seeks experience.
On the contrary, the value table needs sophisticated update rules (temporal difference learning) to fill its values, and it takes time for these values to converge to reliable numbers for use. In other words, the value table is slow to achieve. However, it comes at a great price. Once the value table converges, we can immediately derive the optimal policy and solve the problem. This is not the case for the replay buffer. Even when you have a buffer of billion items, it does not mean you can have something useful for inference.
They are analogous to two forms of memory in the brain: episodic and semantic memory. One is quick, and the other slow. Both can last long and serve the same purpose of value estimation. Besides episodic and semantic memory, another form of memory often found in RL is working memory whose lifespan is shorter. However, its usage is not targeted to a specific task like value computing but is more about supporting other modules and functionality. We can summarise three forms of memory in the table below.
| Form | Lifespan | Plasticity | Example |
|---|---|---|---|
| Working Memory | Short-term | Quick | - 1 episode is one day - Last for 1 day - Build memory instantly |
| Episodic Memory | Long-term | Quick | - Persists across agent’s lifetime - Last for several years - Build memory instantly |
| Semantic Memory | Long-term | Slow | - Persists across agent’s lifetime - Last for several years - Take time to build memory |
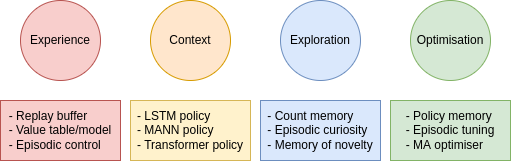
Since the forms of these memories are different, they are used for different purposes and motivations. For example, working memory builds the context for prediction (world model) or action-making within one episode. Especially in partially-observable MDP, the observation at a single timestep is too limited to make a good action, the agent must maintain a working memory of recent timesteps to build a complete picture of the surroundings. Episodic memory can store critical experiences for the agent to make decisions or build value estimation as stated earlier. Yet, the same functional episodic memory can also be used to assist exploration by guiding the agent to novel states. We conclude this post with a picture summarising several applications of memory in RL and their implementation examples.